Upozornění:Poznámky jsem vytvořil ke přípravě na státnice, takže jsou povrchní (obsahují pouze definice, tvrzení a příklady, žádné důkazy a velmi málo obsahu z konce semestru). Ke studiu na zkoušku se můžou hodit, ale rozhodně bych se neučil pouze z nich.
Úvodní informace
Tato stránka obsahuje moje poznámky z přednášky Roberta Šámala z akademického roku 2020/2021 (MFF UK). Pokud by byla někde chyba/nejasnost, nebo byste rádi něco přidali, tak stránku můžete upravit pull requestem (případně mi dejte vědět na mail).
Úvod
Definice (prostor jevů) je F⊆P(Ω), pokud
∅∈F a Ω∈F
je uzavřený na doplňky: A∈F⟹Ω∖A∈F a
je uzavřený na sjednocení: A1,A2,…∈F⟹⋃i=1∞Ai∈F
Množině Ω říkáme prostor elementárních jevů.
Definice (pravděpodobnost) je funkce P:F↦[0,1] se nazývá pravděpodobnost, pokud
P(∅)=0,P(Ω)=1 a
P(⋃i=1∞Ai)=∑i=1∞P(Ai) pro libovolnou posloupnost po dvou disjunktních jevů A1,A2,…∈F
Definice (pravděpodobnostní prostor) je trojice (Ω,F,P) taková, že
Ω=∅ je libovolná množina (prostor elementárních jevů),
F⊆P(Ω) je prostor jevů, a
P je pravděpodobnost přiřazující každému jevu pravděpodobnost.
Příklad (pravděpodobností prostory):
konečný s uniformní pravděpodobností:Ω je libovolná konečná množina, P(A)=∣A∣/∣Ω∣
diskrétní:Ω je libovolná spočetná množina
spojitý:Ω⊆Rn, F vhodná, P definován přes integrál (viz dále)
Znázornění konečného prostoru s uniformní pravděpodobností. Dvojice hodů kostkou jsou elementární jevy (∈Ω), vyznačené množiny jsou měřené jevy (∈F).
Lemma (základní vlastnosti):∀A,B∈F platí
P(A)+P(AC)=1
A⊆B⟹P(A)≤P(B)
P(A∪B) = P(A)+P(B)−P(A∩B)
P(A1∪A2∪…)≤∑P(Ai)
Definice (podmíněná pravděpodobnost): pokud A,B∈F a P(B)>0, tak definujeme podmíněnou pravděpodobnost A při B jako
P(A∣B)=P(B)P(A∩B)
Věta (o úplně pravděpodobnosti):Pokud A1,…,An∈F a P(A1∩A2∩…∩An)>0, tak
P(A1∩A2∩…∩An)=P(A1)P(A2∣A1)P(A3∣A2∪A1)…
Definice (rozklad): spočetný systém množin Bi∈F je rozklad Ω, pokud
Bi∩Bj=∅ pro i=j a
⋃iBi=Ω
Věta (rozbor všech možností):Pokud A1,…,An∈F je rozklad Ω a A∈F, pak
P(A)=i∑P(A∣Bi)P(Bi)
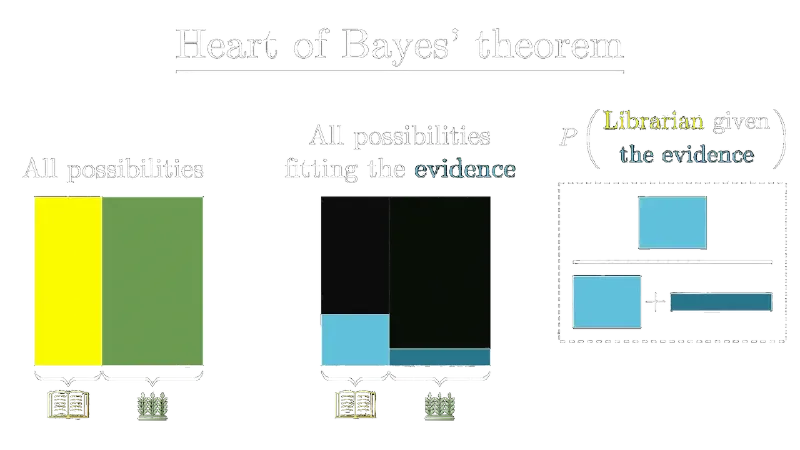
Věta (Bayesova):pokud B1,B2,… je rozklad Ω, A∈F a P(A),P(Bj)>0, tak
Věta řeší problém, kdy máme jev H (hypotézu), který chceme spočítat, když platí jev E (evidence). Použitím Bayesova vzorce dostáváme
P(H∣E)=P(E)P(E∣H)P(H)
což intuitivně dává smysl – při pravděpodobnosti H∣E musíme zohlednit pravděpodobnost E.
Poznámka: 3b1b udělal o Bayesově větě pěkné video, ze kterého jsem vykradl obrázek výše.
Příklad:
Definice (nezávislost jevů): dva jevy jsou nezávislé, pokud P(A∩B)=P(A)P(B)
Diskrétní náhodné veličiny
Definice (diskrétní náhodná veličina): Pro pravděpodobnostní prostor Ω,F,P mějme funkci X:Ω↦R nazvene diskrétní náhodná veličina, pokud Im(X) (obor hodnot) je spočetná množina a pokud ∀x platí
{ω∈Ω:X(ω)=x}∈F
Příklad (použití náhodných veličin):
hodíme na terč a měříme vzdálenost od středu
házíme kostkou, dokud nepadne šestka a pak nás zajímá počet hodů
Definice (pravděpodobnostní funkce) (pmf) diskrétní náhodné veličiny X je funkce pX:R↦[0,1] taková, že
pX(x)=P(X=x)=P({ω∈Ω:X(ω)=x})
Rozdělení
Bernoulli
X⋅ počet orlů při jednom hodu nespravedlivou mincí (značíme X∼Bern(p))
pX(1)=p a pX(0)=1−p, jinak pX(k)=0
Binomiální
X… počet orlů při n hodech nespravedlivou mincí (značíme X∼Bin(n,p))
méně očividně pX(k)=(kn)pk(1−p)n−k
chceme, aby se k hodů trefilo a n−k netrefilo
Poissonovo
limita Bin(n,λ/n), popisuje např. počet mailů za hodinu
Geometrické
X… kolikátým hodem mincí padl první orel (značíme X∼Geom(p))
pX(k)=(1−p)k−1p
chceme, aby se prvních k hodů trefilo a poslední netrefil
Střední hodnota
Definice (střední hodnota diskrétní n.v.)E(X) je definována jako
E(X)=x∈Im(X)∑xP(X=x)
pokud součet dává smysl.
Věta (LOTUS):pokud X je n.v. a g reálná funkce, tak
E(g(X))=x∈Im(X)∑g(x)P(X=x)
Lemma (vlastnosti střední hodnoty):nechť X,Y jsou diskrétní n.v. a a,b∈R; pak
pokud P(X≥0)=1 a E(X)=0, tak P(X=0)=1
pokud E(X)≥0, tak P(X≥0)>0
E(aX+bY)=aE(X)+bE(Y) (linearita střední hodnoty)
Definice (rozptyl/variance) n.v. nazveme
var(X)=E((X−EX)2)
má intuitivní význam – jedná se o očekávanou vzdálenost (2) od střední hodnoty
Definice (směrodatná odchylka) je
var(x)
Věta:var(X)=E(X2)−E(X)2
Přehled parametrů známých rozdělení:
Rozdělení
E
var
Bern(p)
p
p(1−p)
Bin(n,p)
np
np(1−p)
Geom(p)
1/p
np(p21−p)
Pois(λ)
λ
λ
Sdružené rozdělení
Definice: pro diskrétní n.v. X,Y definujeme jejich sdruženou pravděpodobnostní funkci (joint pmf) pX,Y:R2↦[0,1] jako
pX,Y(x,y)=P({ω∈Ω:X(ω)=x∧Y(ω)=y})
(👀): z pX,Y (sdruženého) jde pX,pY (marginální) zjistit, jednoduše, zpětně ne vždy.
Definice (nezávislé náhodné veličiny): veličiny X,Y jsou nezávislé, pokud ∀x,y∈R platí
P(X=x,Y=y)=P(X=x)P(Y=y)
neboli
pX,Y(x,y)=pX(x)pY(y)
Věta (součin n.n.v.):pro nezávislé diskrétní veličiny X,Y platí
E(XY)=E(X)E(Y)
Definice (podmíněné rozdělení): pro X,Y d.n.v. a A∈F definujeme
pX∣A(x)=P(X=x∣A)pX∣Y(x∣y)=P(X=x∣Y=y)
Příklad: Pro X,Z výsledky dvou nezávislých hodů šestihranou kostkou a Y=X+Z nás zajímá pX∣Y(6∣10) (jaká je šance, že na kostce padla hodnota 6, když součet na obou byl 10). Můžeme spočítat ze sdruženého:
Definice (náhodná veličina) na (Ω,F,P) je zobrazení X:Ω↦R, které pro každé x∈R splňuje
{ω∈Ω:X(ω)≤x}∈F
(👀): diskrétní n.v. je náhodná veličina (pro tu platí rovnost, kterou posčítáme).
Definice (distribuční funkce) (DNF) n.v. je funkce
FX(x)=P(X≤x)=P({ω∈Ω:X(ω)≤x})
(👀):
FX je neklesající
limx→−∞FX(x)=0
limx→∞FX(x)=1
FX je zprava spojitá
Definice (spojitá náhodná veličina): n.n.v. je spojitá, pokud existuje nezáporná reálná funkce fx (hustota) t.ž.
FX(x)=P(X≤x)=∫−∞tfX(t)dt
Rozdělení
Příklad (uniformní rozdělení): n.v. X má na [a,b] uniformní rozdělení, pokud má hustotní funkci
fX(x)={b−a10x∈[a,b]jindy
Distribuční a hustotní funkce uniformního rozdělení.
Příklad (exponenciální rozdělení): n.v. X má exponenciální rozdělení, pokud má distribuční funkci
FX(x)={01−e−λxx≤0x≥0
Distribuční a hustotní funkce exponenciálního rozdělení.
Příklad (normální rozdělení): n.v. X má standardní normální rozdělení, pokud má hustotní funkci
fX(x)=2π1e−x2/2
μ=0 a σ=1." loading="lazy">Distribuční a hustotní funkce normálních rozdělení. Standardní je pro μ=0 a σ=1.
Definice (kvantilová funkce): pro distribuční funkci F definujeme kvantilovou funkci Q:[0,1]↦R jako
QX(p)=min{x∈R:p≤F(x)}
(👀): pokud je FX spojitá, pak QX=FX−1
Definice (střední hodnota s.n.v.) je definována jako
E(X)=∫−∞∞xfX(x)dx
pokud integrál dává smysl.
Poznámka: LOTUS, linearita, rozptyl fungují také (přesně tak, jak bychom čekali)
Definice (kovariance): pro n.v. X,Y je jejich kovariance definována jako
cov(X,Y)=E((X−EX)(Y−EY))
Lemma:
cov(X,Y)=E(XY)−E(X)E(Y)
X,Y nezávislé ⟹cov(X,Y)=0
Nerovnosti
Věta (Markovova nerovnost):nechť náhodná veličina splňuje X≥0; pak
P(X≥a)≤aE(X)
(👀): říká, že pravděpodobnost, že X je alespoň a je nejvýše E/a, což intuitivně dává smysl
pro a=E může být X střední hodnota nejhůř vždy
pro a=E/2 dostáváme 21 – kdyby byla X střední hodnota častěji než 21, tak posčítáním přes všechny hodnoty dostáváme spor, střední hodnota by musela být vyšší
Limitní věty
Věta (zákon velkých čísel):nechť X1,…,Xn jsou stejně rozdělené n.n.v. se stř. hodnotou μ a rozptylem σ2. Označme Sn=(X1+…+Xn)/n (tzv. výběrový průměr). Pak platí
n→∞limSn=μ
skoro jistě (tj. s pravděpodobností 1).
Věta říká, že je smyslupné průměrovat n.n.v. (s větším n se přibližuje k μ).
Věta (centrální limitní věta):nechť X−1,…,Xn jsou n.n.v. se střední hodnotou μ a rozptylem σ2. Označme Yn=((X1+…+Xn)−nμ)/(nσ). Pak Yn→dN(0,1). Neboli pokud Fn je distribuční funkce Yn, tak
n→∞limFn(x)=Φ(x)∀x∈R
Tedy (vhodně přeškálovaný) součet n.n.v. Xi konverguje ke standardnímu normálnímu rozdělení.
Tahák
Ke zkoušce byla povolena A4 s libovolnými poznámkami, tady jsou moje (dostupné i v PDF).

 Pravděpodobnost a Statistika I
Pravděpodobnost a Statistika I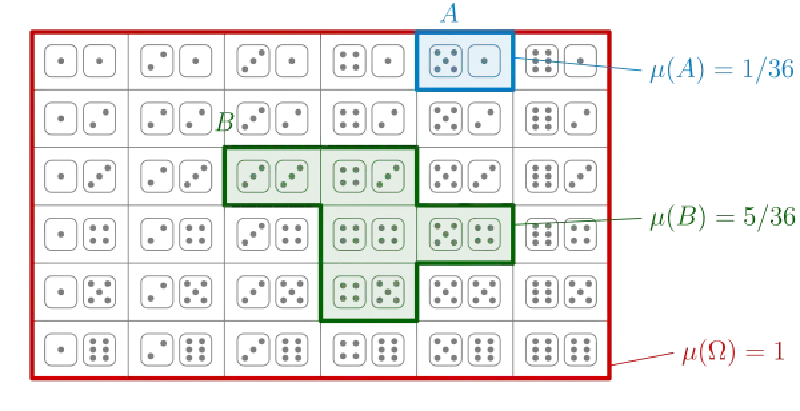


 a ." loading="lazy">
a ." loading="lazy">
