
 Mining Massive Datasets
Mining Massive Datasets
Preface
This website contains my lecture notes from a lecture by Artur Andrzejak from the academic year 2022/2023 (University of Heidelberg). If you find something incorrect/unclear, or would like to contribute, feel free to submit a pull request (or let me know via email).
Note that the notes only cover the topics required for the exam, which are only a portion of the contents of the lecture.
Lecture overview
- Spark architecture and RDDs [slides]
- Spark Dataframes + Pipelines [slides]
- Recommender Systems 1 [slides]
- Recommender Systems 2 [slides]
- Page Rank 1 [slides]
- Page Rank 2 [slides]
- Locality Sensitive Hashing 1 [slides]
- Locality Sensitive Hashing 2 [slides]
- Frequent itemsets + A-Priori algorithm [slides]
- PCY extensions [slides]
- Online bipartite matching + BALANCE [slides]
- Mining data streams 1 [slides]
- Mining data streams 2 [slides]
Programming and Frameworks
PySpark
RDDs [cheatsheet]
Main data structure are RDDs (resilient distributed datasets):
- collection of records spread across a cluster
- can be text line, string, key-value pair, etc.
Two operation types:
- transformations: lazy operations to build RDDs from other RDDs
- actions: return a result or write it to storage
DataFrames [cheatsheet]
PySpark’s other main data structure are DataFrames:
- table of data with rows and (named) columns
- has a set schema (definition of column names and types)
- lives in partitions (collections of rows on one physical machine)
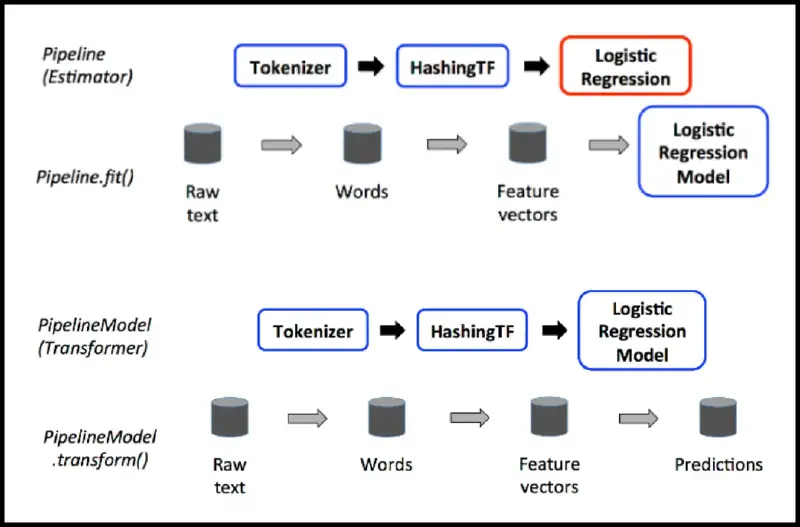
ML with Spark
- mainly lives in
MLlib, which consists ofpyspark.ml(high-level API) andpyspark.mllib(low-level API)
- is based on pipelines, which set up everything, including
- data cleaning
- feature extraction
- model training, validation, testing
- they use DataFrames
Definition (Transformer): an algorithm which transforms one DataFrame into another
- uses a
transform()method to activate (i.e. transform the DataFrame)
Definition (Estimator): an algorithm which can be fit on a DataFrame to produce a Transformer
- abstracts the concept of a learning algorithm
- contains a
fit()function, which when called produces a Transformer
Definition (Pipeline): an object which contains multiple Transformers and Estimators
- a complete untrained pipeline is an Estimator
- after calling
fit(), all estimators become transformers!
Spark Streaming
General idea is to:
- split the stream into batches of seconds,
- perform RDD operations and lastly
- return the results of the RDD operations in batches
DStream (discretized stream) – container for a stream, implemented as a sequence of RDDs
| |
Recommender Systems
Problem: set of customers , set of items , utility function (set of ratings)
- usually
- can be stored in a utility matrix:
| Alice | Bob | Carol | David | |
|---|---|---|---|---|
| Star Wars | ||||
| Matrix | ||||
| Avatar | ||||
| Pirates |
Note: for some reason, this matrix is while all other notation is (like , for example). It’s confusing, I’m not sure why we’ve defined it this way.
Goal: extrapolate unknown ratings from the known ones.
Collaborative filtering (CF)
Idea: take known ratings of other similar items/users.
User-user CF
- find set of other users whose ratings are similar to user ’s ratings
- estimate ’s ratings based on ratings of users from
Algorithm:
- let be vector of user ’s ratings and the set of neighbors of
- predicted rating of user for item is
To calculate similarity, we can use a few things:
- Cosine similarity measure (angle between vectors)
- where
- problem 1: missing ratings become low ratings
- problem 2: doesn’t account for bias (some users rate higher on average)
- Pearson similarity measure (angle between normalized + offset vectors without zero entries)
- where are the indexes that are non-zero for both and
- problem 1 fixed by only taking items rated by both users
- problem 2 fixed by offsetting by average
This way of writing Pearson is hiding what’s really going on, so here is a nicer way: let and be formed from vectors by removing the indexes where either one is zero. Then the Pearson similarity measure can be calculated like such:
To calculate neighbourhood, we can do a few things:
- set a threshold for similarity and only take those above
- take the top similar users, whatever their similarities are
Item-item CF
Analogous to User-user: for rating item , we find items rated by user that are similar (as in rated similarly by other users). To do this, we can again use , obtaining
The improved version has a slightly different baseline to User-User, namely
where mean item rating rating deviation of user rating deviation of item .
Pros/Cons
- [+] Works for any kind of item (no feature extraction)
- [-] Cold start (needs user data)
- [-] Sparsity (user/rating matrix is sparse)
- [-] First rater (can’t recommend an item that hasn’t been rated)
- [-] Popularity bias (tends to recommend popular items)
Content-based recommendations
Main idea: create item profiles for each item, which is a vector of features:
- author, title, actor, director, important words
- can be usually encoded as a binary vector with values getting fixed positions in the vector
- can also be mixed (binary encoding + floats where appropriate)
For creating user profiles, we can do a weighted average (by rating) of their item profiles:
For matching User and Item (i.e. determining rating), we can again use cosine similarity between the user profile and the item.
Pros/Cons
- [+] No need for user data (no cold start or sparsity)
- [+] Can recommend new + unpopular items
- [+] Able to provide explanations (why was that recommended?)
- [-] Finding good features is hard
- [-] Recommendations for new users
- [-] Overspecialization – unable to exploit quality judgement from other users
Latent factor models
Merges Content-Based Recommenders (rating is a product of vectors) and Collaborative filtering (weighted sum of other ratings from the utility matrix) – use user data to create the item profiles! We’ll do this by factorizing the matrix into user matrix and item matrix such that we minimize SSE

What we want to do is split the data into a training set, which we use to create the matrices, and the testing set, on which the matrices need to perform well. To do this well, we’ll use regularization, which controls for when the data is rich and when it’s scarce (lots of zeroes in s and s):
for user-set regularization parameters.
Link Analysis
Flow formulation
Problem: we have pages as a directed graph. We want to determine the importance of pages based on how many links lead to it. I.e. if page of importance has outgoing links, each link gets importance . Formally:
Can be expressed as a system of linear equations to be solved (Gaussian elimination).
Matrix formulation
Can also be formulated as an adjacency matrix ,
then we can define the flow equation as
meaning that we’re looking for the eigenvector of the matrix. Since the matrix is stochastic (columns sum to 1), its first eigenvector has eigenvalue 1 and we can find it using power iteration (see the PageRank formulation below).
This, however, has two problems:
- dead ends (when a page has no out-links); makes the matrix non-stochastic!
- spider traps (when there is no way to get out of a part of the graph)
Both are solved using teleports – during each visit, we have a probability of to jump to a random page ( usually ). In a dead-end, we teleport with probability .
Using this, we get the Google PageRank equation:
Practical computation
To reduce the matrix operations, we can rearrange the matrix equation and get
Algorithm (PageRank):
- set
- repeat until :
- power method iteration: , otherwise if in-degree of is
- vector normalization:
When we don’t have enough RAM to fit the whole matrix , we can read and update it by vertices (it’s sparse so we’d likely be storing it as a dictionary):
| Source | Degree | Destination |
|---|---|---|
I.e. do .
When we can’t even fit into memory, we can break it into blocks that do fit into memory and scan and . This, however, is pretty inefficient – we can instead use the block-stripe algorithm, which breaks by destinations instead so we don’t need to repeatedly scan it!
Each block will only contain the destination nodes in the corresponding block of .
| Destination | Source | Degree | Destination |
|---|---|---|---|
Topic-Specific PageRank
We can bias the random page walk to teleport to relevant pages (from set ). For each teleport set , we get different vector . This changes the PageRank formulation like so:
TrustRank
Addresses issues with spam farms, which are pages that just point to one another. The general idea to fix this is to use a set of seed pages from the web and identify the ones that are „good“, i.e. trusted. Then perform topic-specific pagerank with trusted pages, which propagates the trust to other pages. After this, websites with trust below a certain threshold are spam.
- to pick seed pages, we can use PageRank and pick the top , or use trusted domains
- in this case, a page confers trust equal to
We can use TrustRank for spam mass estimation (i.e. estimate how much rank of a page comes from spammers):
- : PageRank of page
- : PageRank of page with teleport into trusted pages only
- : how much rank comes from spam pages
- Spam mass of :
Locality Sensitive Hashing
Goal: find near-neighbors in high-dimensional spaces:
- points in the same cluster
- pages with similar words
General idea:
- Shingling: convert items (in our case documents) into sets
- Min-hashing: convert large sets into shorter signatures
- Locality-Sensitive Hashing: identify pairs of signatures likely to be similar
- Final filtering: get the final few candidate pairs and compare them pairwise
Preface
Definition (hash function): function , where is a large domain space and a small range space (usually integers).
- for example with prime
They are very useful for implementing sets and dictionaries (have an array to store the elements in and use a good hash function to map them; dynamically grow/shrink as needed).
Shingling
For a document, take a sliding window of size . Then -shingles for the given document are all sequences of consecutive tokens from the document.
- if the shingles are long, they can also be compressed using some hash function
Min-hashing
The shingling sets are very large, so we have to find a way to measure how similar they are. What we want to measure is their Jaccard similarity, which is
To do this, we’ll compute signatures, which are shorter but should have the same Jaccard similarity as the original set. To compute a signature, we take many random hash function (for example random permutations), hash all values from the set of shingles and take the minimum. Then the list of all those minimal values is the signature.
- in practice, we do for random integers, prime and size of shingles
For example:
- permutation
- set of shingles (as a bit array)
- resulting min-hash: (by shingle mapping to index )
It turns out that
- the intuition is that if the sets of shingles are very similar, randomly shuffling them in the same way and then taking the minimum value should, with a high probability (well, with probability of the similarity measure), be equal
Locality-Sensitive Hashing
Our goal now is to find documents with Jaccard similarity at least (e.g. ). To do this, we will hash parts of the signature matrix:
- take matrix and divide it into bands of rows
- for each band, hash its portion of each column to a hash table with buckets
- candidate column pairs are those that hash to the same bucket for band

We want to tune and to catch most similar pairs but few non-similar pairs:
- let and (we have signatures of length )
- are similar:
- probability for one band to hash to the same bucket is
- probability that and are not found is
- i.e. of similar pairs are not found – false negatives
- are similar:
- probability for one band to hash to the same bucket is
- probability that and ARE similar is
- i.e. pairs of docs with similarity become candidate pairs – false positives
Plotting the probabilities with variable , we get the S-curve:

Association Rule Discovery
Goal (the market-basket model): identify items that are bought together by sufficiently many customers (if someone buys diaper and baby milk, they will also buy vodka since the baby is probably driving them crazy).
Approach: process the sales data to find dependencies among items
| TID | Items |
|---|---|
| 1 | Bread, Coke, Milk |
| 2 | Vodka, Bread |
| 3 | Vodka, Coke, Diaper, Milk |
| 4 | Vodka, Bread, Diaper, Milk |
| 5 | Coke, Diaper, Milk |
Definition (frequent itemsets): sets of items that frequently appear together
- support for itemset : number of baskets containing all items
- i.e. support for from the table above is
- given a support threshold , we call a set frequent, if they appear in at least baskets
Definition (association rule): an association rule has the form
and essentially states that if a basket contains the set , then it also contains set
- we want high confidence: if then
- we also want high rule support: is large
Definition (confidence): of an association rule is the probability that it applies if , namely
Definition (interest): of an association rule is the difference between confidence and the fraction of baskets that contain , namely
Problem: we want to find all association rules with and .
- find all frequent itemsets (those with )
- recipes are usually stored on disks (they won’t fit into memory)
- association-rule algorithms read data in passes – this is the true cost
- hardest is finding frequent pairs (number of larger tuples drops off)
- approach 1: count all pairs using a matrix bytes per pair
- approach 2: count all pairs using a dictionary bytes per pair with count
- smarter approaches: A-Priori, PCY (see below)
- use them to generate rules with :
- for every , generate rule : since is frequent, is also frequent
- for calculating confidences, we can do a few things:
- brute force go brrrrrr
- use the fact that if is below confidence, so is
A-Priori Algorithm
- a two-pass approach to finding frequent item sets
- key idea: monotonicity: if a set appears at least times, so does its every subset
- if item doesn’t appear in baskets, neither can any set that includes it
Algorithm (A-Priori):
- pass: count individual items
- pass: count only pairs where both elements are frequent

Can be generalized for any by again constructing candidate -tuples from previous pass and then passing again to get the truly frequent -tuples.
PCY Algorithm
Observation: in pass of A-Priori, most memory is idle:
- also maintain a hash table with as many buckets as fit in memory
- hash pairs into buckets (just their counts) to speed up phase 2
- if they were frequent, their bucket must have been frequent too
Algorithm (PCY (Park-Chen-Yu)):
- pass: count individual items + hash pairs to buckets, counting them too
- between passes: convert the buckets into a bit-vector:
- if a bucket count exceeded support
- if it did not
- between passes: convert the buckets into a bit-vector:
- pass: count only pairs where
- both elements are frequent (same as A-Priori) and
- the pair hashes to a bucket whose bit is frequent

Online Advertising
Initial problem: find a maximum matching for a bipartite graph where we’re only given the left side and the right side is revealed one-by-one. The obvious first try is a greedy algorithm (match with first available)
- has a competitive ratio of 1
Revised problem: left side are advertisers, right side terms to advertise on; we know
- the bids advertisers have on the queries,
- click-through rate for each advertiser-query pair (for us, all are equal),
- budget for each advertiser (for us, all have budget ) and
- limit on the number of ads to be displayed with each search query (for us, limit to )
We want to respond to each search query with a set of advertisers such that:
- size of the set is within bounds,
- each advertiser has a bid on the search query and
- each advertiser has enough budget to pay for the ad
Greedy: pick the first available advertiser
- again has a competitive ratio of
BALANCE: pick the advertiser with the largest unspent budget (largest balance)
- has a competitive ratio of 2 (for advertisers and budget )
- in general, has a competitive ratio of (same budget for advertisers, arbitrary number of advertisers, bids are 0 or 1)
- no online algorithm has better competitive ratio for this case
Mining Data Streams
For our purposes, a stream is a long list of tuples of some values.
Stream Filtering
Problem: given a stream and a list of keys , determine which stream elements are in
- using a hash table would be great, but what if we don’t have enough memory?
- example: spam filter (if an email comes from them, it’s not spam if it’s a good address)
First-cut solution
- create a bit array of bits of s and let
- get a hash function and hash , setting where they hash
- if an element of the stream hashes to:
- , it can’t be in
- , it could be in (we’d have to check to make sure)
The probability that a target gets at least one hash (which equals the false positive rate) is
Bloom filter
Create independent hash functions, setting s for all element’s hashes:
However, to generate a false positive rate, all of the hash functions have to get a hit, so:
The minimum of this function (wrt. ) is :

Stream Sampling
Fixed portion
Goal: store a fixed portion of the stream (for ex. 1/10)
Naive solution: pick randomly and hope for the best
- really bad idea – what if we want to know, how many queries are duplicates?
- we’d have to pick both, the probability of which is not the same as picking one
Better solution: pick by value, not by position (i.e. pick 1/10 of users)
- generalized: key is some subset of the tuple, for ex. (user; search; time)
- use hashing to buckets to determine which elements to sample
Fixed size (Reservoir Sampling)
Goal: store a fixed number of elements of the stream
Algorithm (Reservoir Sampling):
- store all first elements
- when an element number comes in, with probability , keep it (replacing one of the current elements uniformly randomly), else discard it
This ensures that after elements, all elements have a probability to be currently sampled3.
Stream Counting
Goal: count the number of distinct elements in the stream
- elements are picked from a set of size
- we can’t store the whole , we’d like to approximate with the smallest error
Flajolet-Martin
Algorithm (Flajolet-Martin):
- pick a hash function that maps each of the elements to at least bits
- let be the number of trailing zeroes in
- estimated number of distinct elements is
Intuitively, hashes with equal probability, so the probability that we get a hash with trailing zeroes is (i.e. we have to hash at least others before).
We can generalize this concept to counting moments: for being the number of times element appears in the stream , we define the -th moment as
- number of distinct elements
- number of elements
- the surprise number (measure of how uneven the distribution is)
- for sequence ,
- for sequence ,
AMS Algorithm
Algorithm (AMS (Alon-Matias-Szegedy)):
- pick and keep track of „approximate“ variables
- the more variables there are (say ), the more precise the approximation is
- for each , we store the ID and the count of the given item
- to instantiate it, pick some random time (we’ll fix it later if we don’t know )
- set and count it from then on (to )
- the estimate of the nd moment is then
- for rd, we can use
Fixups (we don’t know the size of the stream)
- suppose we can store at most variables
- use Reservoir sampling to sample variables, counting from when they are replaced
- since we are guaranteed that any variable is selected with uniform probability over the whole stream (and its counter is reset at that time), AMS works
Let’s prove that this works for the nd moment for one variable. We want to prove that . Let be the number of times the item at index appears from then on. We get
let be left side and the right. If , consider set matched in but not in . Now consider adjacent to : every one of those must be matched in (for those not to be) so . Also, , since otherwise the optimal algorithm couldn’t have matched all girls in . Since , we get the desired bound after substituting for . ↩︎
Here is the proof from the lecture:
 ↩︎
↩︎Shown by induction – after element arrives:
- for element in , the probability that the algorithm keeps it this iteration is
- the probability that the element is in at time is therefore